This is a pretty short compilation about data formats and I will ignore JSON, XML and a lot of other formats here.
From my point of view – this one presentation is very important to understand difference between different formats (I used a lot of other data sources, just in case):
CSV
The CSV (“Comma Separated Values”) file format is often used to exchange data between differently similar applications. The CSV Format:
- Each record is one line – Line separator may be LF (0x0A) or CRLF (0x0D0A), a line separator may also be embedded in the data (making a record more than one line but still acceptable).
- Fields are separated with commas.
- Leading and trailing whitespace is ignored – Unless the field is delimited with double-quotes in that case the whitespace is preserved.
- Embedded commas – Field must be delimited with double-quotes.
- Embedded double-quotes – Embedded double-quote characters must be doubled, and the field must be delimited with double-quotes.
- Embedded line-breaks – Fields must be surrounded by double-quotes.
- Always Delimiting – Fields may always be delimited with double quotes, the delimiters will be parsed and discarded by the reading applications.
Example:

Parquet
The Parquet file format incorporates several features that make it highly suited to data warehouse-style operations:
- Columnar storage layout. A query can examine and perform calculations on all values for a column while reading only a small fraction of the data from a data file or table.
- Flexible compression options. The data can be compressed with any of several codecs. Different data files can be compressed differently. The compression is transparent to applications that read the data files.
- Innovative encoding schemes. Sequences of identical, similar, or related data values can be represented in ways that save disk space and memory. The encoding schemes provide an extra level of space savings beyond the overall compression for each data file.
- Large file size. The layout of Parquet data files is optimized for queries that process large volumes of data, with individual files in the multi-megabyte or even gigabyte range.
Data Structure:

There are three types of metadata: file metadata, column (chunk) metadata and page header metadata. All thrift structures are serialized using the TCompactProtocol.
Example:
4-byte magic number “PAR1”
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
…
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
…
<Column N Chunk 2 + Column Metadata>
…
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
…
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number “PAR1”
Example:
We will create table to store text data

Load the data into the table:

Check the data
ORC
The Optimized Row Columnar (ORC) file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data.
Compared with RCFile format, for example, ORC file format has many advantages such as:
- a single file as the output of each task, which reduces the NameNode’s load
- Hive type support including datetime, decimal, and the complex types (struct, list, map, and union)
- light-weight indexes stored within the file
- skip row groups that don’t pass predicate filtering
- seek to a given row
- block-mode compression based on data type
- run-length encoding for integer columns
- dictionary encoding for string columns
- concurrent reads of the same file using separate RecordReaders
- ability to split files without scanning for markers
- bound the amount of memory needed for reading or writing
- metadata stored using Protocol Buffers, which allows addition and removal of fields
Example:
CREATE TABLE test_details_txt( visit_id INT, store_id SMALLINT) STORED AS TEXTFILE; CREATE TABLE test_details_orc( visit_id INT, store_id SMALLINT) STORED AS ORC; — Load into Text table LOAD DATA LOCAL INPATH ‘/home/user/test_details.txt’ INTO TABLE test_details_txt; — Copy to ORC table INSERT INTO TABLE test_details_orc SELECT * FROM test_details_txt;
Hive
Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop. The traditional SQL queries must be implemented in the MapReduce Java API to execute SQL applications and queries over a distributed data. Hive provides the necessary SQL abstraction to integrate SQL-like Queries (HiveQL) into the underlying Java API without the need to implement queries in the low-level Java API. Since most of the data warehousing application work with SQL based querying language, Hive supports easy portability of SQL-based application to Hadoop.
File Structure
An ORC file contains groups of row data called stripes, along with auxiliary information in a file footer. At the end of the file a postscript holds compression parameters and the size of the compressed footer.
The default stripe size is 250 MB. Large stripe sizes enable large, efficient reads from HDFS.
The file footer contains a list of stripes in the file, the number of rows per stripe, and each column’s data type. It also contains column-level aggregates count, min, max, and sum.
This diagram illustrates the ORC file structure:
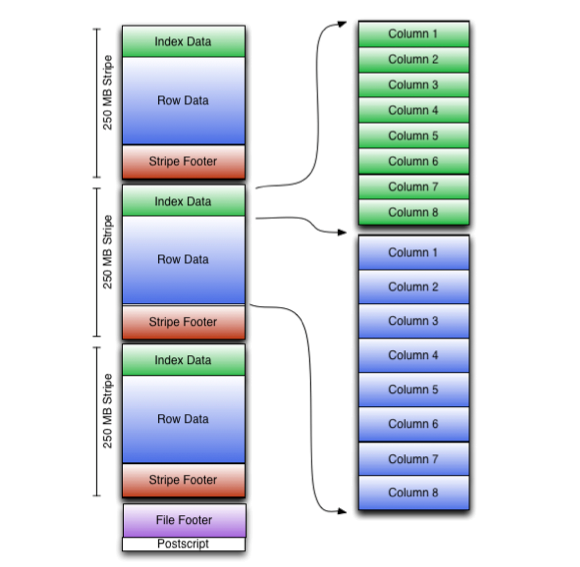
Stripe Structure
As shown in the diagram, each stripe in an ORC file holds index data, row data, and a stripe footer.
The stripe footer contains a directory of stream locations. Row data is used in table scans.
Index data includes min and max values for each column and the row positions within each column. (A bit field or bloom filter could also be included.) Row index entries provide offsets that enable seeking to the right compression block and byte within a decompressed block. Note that ORC indexes are used only for the selection of stripes and row groups and not for answering queries.
Having relatively frequent row index entries enables row-skipping within a stripe for rapid reads, despite large stripe sizes. By default every 10,000 rows can be skipped.
With the ability to skip large sets of rows based on filter predicates, you can sort a table on its secondary keys to achieve a big reduction in execution time. For example, if the primary partition is transaction date, the table can be sorted on state, zip code, and last name. Then looking for records in one state will skip the records of all other states.
A complete specification of the format is given in the ORC specification.
HDFS
Spark could process data at HDFS (Hadoop Distributed File System). HDFS is a Java-based file system that provides scalable and reliable data storage, and it was designed to span large clusters of commodity servers. HDFS has demonstrated production scalability of up to 200 PB of storage and a single cluster of 4500 servers, supporting close to a billion files and blocks.
HDFS is a distributed file system designed to store large files spread across multiple physical machines and hard drives. Spark is a tool for running distributed computations over large datasets. Spark is a successor to the popular Hadoop MapReduce computation framework. Together, Spark and HDFS offer powerful capabilities for writing simple code that can quickly compute over large amounts of data in parallel.
From a user’s perspective, HDFS looks like a typical Unix file system. There is a root directory, users have home directories under /user, etc. However, behind the scenes all files stored in HDFS are split apart and spread out over multiple physical machines and hard drives. As a user, these details are transparent; you don’t need to know how your files are broken apart or where they are stored.
