Once again, the key thing about queries in Cassandra (my previous article about it) – there is no way to do joins there. So you should be very accurate with the model of the database. Anyway, if there is a strong need to perform relational queries over data stored in Cassandra clusters – use Spark.
Let’s start with short introduction about Spark, it is:
- A lightning-fast cluster computing technology, designed for fast computation,
- A unified relational query language for traversing over Spark Resilient Distributed Datasets (RDDs),
- Support of a variation of the query language used in relational databases,
- Not about their own database and query language – Spark is about query language and other databases (in our case – Cassandra). You can execute Spark queries in Java applications that traverse over Cassandra column families.
One pretty nice article about Spark is here: http://spark.apache.org/docs/latest/programming-guide.html
Spark and Hadoop difference

What to add?
- They do different things. Hadoop and Apache Spark are both big-data frameworks, but they don’t really serve the same purposes. Hadoop is distributes massive data collections across multiple nodes within a cluster of commodity servers, indexes and keeps track of that data, enabling big-data processing and analytics far more effectively than was possible previously. Spark is a data-processing tool that operates on those distributed data collections; it doesn’t do distributed storage.
- You can use one without the other
- You may not need Spark’s speed
- All data in Hadoop written to disk after every operation, so, is naturally resilient to system faults or failures. Spark uses RDD for it.
Spark and Data Analysis
Spark is great for big data analytics because it:
- Holds data in memory–making it up to *** times faster for certain applications
- Supports multi-stage primitives, which makes it faster than Hadoop with MapReduce
- Offers a convenient, unified programming model for developers, supporting SQL, streaming, machine learning, and graph analytics
- Allows user programs to load big data into a cluster’s memory and query it repeatedly, making it well suited to machine learning algorithms
Spark is also preferable for OLAP (Online Analytical Processing) and Analytics cause of streaming etc, bot not OLTP (Online transaction processing).
RDD Introduction
I’m not going to develop any libraries/frameworks for today, so RDD is a too massive for me (I’ll be using Dataset APIs in my small and simple application). But there is no Spark understanding without RDD cause RDD is a heart and soul of Spark.
Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster (I’ll have no deep overview in parallel operations ). The main abstraction Spark provides is the RDD, which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also use Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. The recovery mechanism of RDDs involves resiliency, which often is explained as rebuilding the state as opposed to recovering.
Spark and Java
Once again – I really liked this one article: http://spark.apache.org/docs/latest/programming-guide.html
But, the long story short, the easiest way to start with RDD – read a collection of lines from the file:
JavaRDD<String> myFile = sc.textFile(“my_text_file.txt”);
Text file RDDs will be created using SparkContext’s textFile method. This method takes an URI for the file (either a local path on the machine, or a hdfs://, s3n://, etc URI) and reads it as a collection of lines. Once created, distFile can be acted upon by dataset operations. Apart from the text files, Spark’s Java API also supports several other data formats to work with groups of files or values in each file.
RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset. For example, the map operation is a transformation that passes each dataset element through a function and returns a new RDD representing the results (for instance in some cases the map operation can return the final result where the reduce is not needed at all). On the other hand, reduce is an action that aggregates all the elements of the RDD using some function and returns the final result to the driver program (although there is also a parallel reduceByKey that returns a distributed dataset).
All transformations in Spark are lazy, in that they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset (e.g. a file). The transformations are only computed when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently. For example, we can realize that a dataset created through map will be used in a reduce and return only the result of the reduce to the driver, rather than the larger mapped dataset.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist (or cache) method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it. There is also support for persisting RDDs on disk, or replicated across multiple nodes.
To illustrate RDD basics, consider the simple program below:
JavaRDD<String> lines = sc.textFile(“data.txt”);
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
The first line defines a base RDD from an external file. This dataset is not loaded in memory or otherwise acted on: lines is merely a pointer to the file. The second line defines lineLengths as the result of a map transformation. Again, lineLengths is not immediately computed, due to laziness. Finally, we run reduce, which is an action. At this point Spark breaks the computation into tasks to run on separate machines, and each machine runs both its part of the map and a local reduction, returning only its answer to the driver program.
If we also wanted to use lineLengths again later, we could add:
lineLengths.persist(StorageLevel.MEMORY_ONLY());
before the reduce, which would cause lineLengths to be saved in memory after the first time it is computed.
And here is the most popular part for people like me: printing elements from RDD.
Another common idiom is attempting to print out the elements of an RDD using rdd.foreach(println) or rdd.map(println). On a single machine, this will generate the expected output and print all the RDD’s elements. However, in cluster mode, the output to stdout being called by the executors is now writing to the executor’s stdout instead, not the one on the driver, so stdout on the driver won’t show these! To print all elements on the driver, one can use the collect() method to first bring the RDD to the driver node thus: rdd.collect().foreach(println). This can cause the driver to run out of memory, though, because collect() fetches the entire RDD to a single machine; if you only need to print a few elements of the RDD, a safer approach is to use the take(): rdd.take(100).foreach(println).
Install Spark
Maven Dependencies
Let’s add a dependency to our project’s Maven configuration file (don’t forget to configure Eclipse to work with Maven projects):
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>chat_connaction_test</groupId> <artifactId>ChatSparkConnectionTest</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>com.datastax.cassandra</groupId> <artifactId>cassandra-driver-core</artifactId> <version>3.1.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.0.0</version> </dependency> <dependency> <groupId>com.datastax.spark</groupId> <artifactId>spark-cassandra-connector_2.11</artifactId> <version>2.0.0-M3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>2.0.0</version>8 </dependency> </dependencies> </project>
Spark Database Connection
Based on the theory, let’s build up our easiest Java + Maven + Spark + Cassandra application to read a table from the database. To establish a database connection use something like this:
SparkConf conf = new SparkConf(). /*To create aSparkContext you first need to build a SparkConf object that contains information about your application. */ setAppName("chat"). //Set a name for your application. setMaster("local"). /* The master URL to connect to, such as "local" to run locally with one thread, "local[4]" to run locally with 4 cores, or "spark://master:7077" to run on a Spark standalone cluster. */ set("spark.executor.memory","1g"). /* You can configure the amount of memory that each executor can consume for the application. Spark uses a 512MB default. */ set("spark.cassandra.connection.host", "127.0.0.1"); /* * - `spark.cassandra.connection.host`: contact points to connect to the Cassandra cluster, defaults to spark master host * - `spark.cassandra.connection.port`: Cassandra native port, defaults to 9042 * - `spark.cassandra.connection.factory`: name of a Scala module or class implementing [[CassandraConnectionFactory]] that allows to plugin custom code for connecting to Cassandra * - `spark.cassandra.connection.keep_alive_ms`: how long to keep unused connection before closing it (default 250 ms) * - `spark.cassandra.connection.timeout_ms`: how long to wait for connection to the Cassandra cluster (default 5 s) * - `spark.cassandra.connection.reconnection_delay_ms.min`: initial delay determining how often to try to reconnect to a dead node (default 1 s) * - `spark.cassandra.connection.reconnection_delay_ms.max`: final delay determining how often to try to reconnect to a dead node (default 60 s) * - `spark.cassandra.auth.username`: login for password authentication * - `spark.cassandra.auth.password`: password for password authentication * - `spark.cassandra.auth.conf.factory`: name of a Scala module or class implementing [[AuthConfFactory]] that allows to plugin custom authentication configuration * - `spark.cassandra.query.retry.count`: how many times to reattempt a failed query (default 10) * - `spark.cassandra.read.timeout_ms`: maximum period of time to wait for a read to return * - `spark.cassandra.connection.ssl.enabled`: enable secure connection to Cassandra cluster * - `spark.cassandra.connection.ssl.trustStore.path`: path for the trust store being used * - `spark.cassandra.connection.ssl.trustStore.password`: trust store password * - `spark.cassandra.connection.ssl.trustStore.type`: trust store type (default JKS) * - `spark.cassandra.connection.ssl.protocol`: SSL protocol (default TLS) * - `spark.cassandra.connection.ssl.enabledAlgorithms`: SSL cipher suites (default TLS_RSA_WITH_AES_128_CBC_SHA, TLS_RSA_WITH_AES_256_CBC_SHA) */ JavaSparkContext sc = new JavaSparkContext(conf);
Spark Example
So, our very first copy & paste ready version of the application:
package com.chatSparkConnactionTest; import static com.datastax.spark.connector.japi.CassandraJavaUtil.javaFunctions; import java.io.Serializable; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import com.datastax.spark.connector.japi.CassandraRow; public class JavaDemo implements Serializable { private static final long serialVersionUID = 1L; public static void main(String[] args) { SparkConf conf = new SparkConf(). setAppName("chat"). setMaster("local"). set("spark.cassandra.connection.host", "127.0.0.1"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> cassandraRowsRDD = javaFunctions(sc) .cassandraTable("chat", "dictionary") .map(new Function<CassandraRow, String>() { @Override public String call(CassandraRow cassandraRow) throws Exception { String tempResult = cassandraRow.toString(); System.out.println(tempResult); return tempResult; } } ); System.out.println("Data as CassandraRows: \n" + cassandraRowsRDD.collect().size()); } }
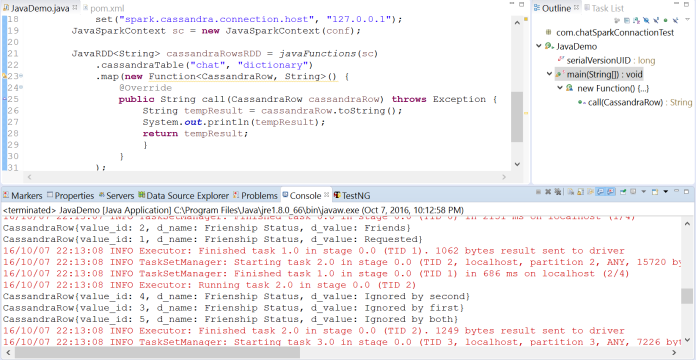
Data Selection
Here is our simple code to read database table: .cassandraTable(“chat”, “dictionary”)
The perfectness of this way to get data from the database is that we need to add .where(“value_id=’1′”) code to the line 23 (on the screenshot above) to filter received data (in my Java + mySQL project I used full query including Select, From, etc).
After that just add a “.” sign and try to order the result set: withASCOrder or withDESC order. Note that it will work only if there is at least one clustering column in the table and a partition key predicate is specified by where clause (that not gonna work for my dictionary table).
When a table is designed so that it include clustering keys and the use case is that only the first n rows from an explicitly specified Cassandra partition are supposed to be fetched, one can find useful the limit method. It allows to add the LIMIT clause to each CQL statement executed for a particular RDD.
External information: https://github.com/datastax/spark-cassandra-connector/blob/master/doc/3_selection.md
Other ways to form JavaRDD object. Beans
The long story short – we also can use beans. All we need here is a dictionary object and main object.
Dictionary.java
package com.chatSparkConnactionTest; public class Dictionary { private String value_id; private String d_name; private String d_value; public String getValue_id() { return value_id; } public void setValue_id(String value_id) { this.value_id = value_id; } public String getD_name() { return d_name; } public void setD_name(String d_name) { this.d_name = d_name; } public String getD_value() { return d_value; } public void setD_value(String d_value) { this.d_value = d_value; } }
JavaDemoRDDBean.java
package com.chatSparkConnactionTest; import static com.datastax.spark.connector.japi.CassandraJavaUtil.javaFunctions; import static com.datastax.spark.connector.japi.CassandraJavaUtil.mapRowTo; import java.io.Serializable; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; public class JavaDemoRDDBean implements Serializable { private static final long serialVersionUID = 1L; public static void main(String[] args) { SparkConf conf = new SparkConf(). setAppName("chat"). setMaster("local"). set("spark.cassandra.connection.host", "127.0.0.1"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> rddBeans = javaFunctions(sc) .cassandraTable("chat", "dictionary", mapRowTo(Dictionary.class)) .map( new Function<Dictionary, String>() { public String call(Dictionary dictionary) throws Exception { return dictionary.toString(); } }); System.out.println(rddBeans.collect().size()); } }
Spark and JSON
There is also a way to form RDD from JSON, but you will find out that DataSet is more preferable here. Anyway, these 2 examples shows us that RDD is almost an array.
To get more details about JSOn please follow the link with an example:
Saving data
As easy as point from the first view…
JavaRDD<Dictionary> rdd = sc.parallelize(dictionary ); javaFunctions(rdd).writerBuilder("chat", "dictionary", mapToRow(Dictionary.class)).saveToCassandra();
Here is updated Dictionary.java:
package com.chatSparkConnactionTest; import java.io.Serializable; public class Dictionary implements Serializable{ private String value_id; private String d_name; private String d_value; public Dictionary(){} public Dictionary (String value_id, String d_name, String d_value) { this.setValue_id(value_id); this.setD_name(d_name); this.setD_value(d_value); } public String getValue_id() { return value_id; } public void setValue_id(String value_id) { this.value_id = value_id; } public String getD_name() { return d_name; } public void setD_name(String d_name) { this.d_name = d_name; } public String getD_value() { return d_value; } public void setD_value(String d_value) { this.d_value = d_value; } }
And here is JavaDemoRDDWrite.java:
package com.chatSparkConnactionTest; import static com.datastax.spark.connector.japi.CassandraJavaUtil.javaFunctions; import static com.datastax.spark.connector.japi.CassandraJavaUtil.mapToRow; import java.io.Serializable; import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; public class JavaDemoRDDWrite implements Serializable { private static final long serialVersionUID = 1L; public static void main(String[] args) { SparkConf conf = new SparkConf(). setAppName("chat"). setMaster("local"). set("spark.cassandra.connection.host", "127.0.0.1"); JavaSparkContext sc = new JavaSparkContext(conf); List<Dictionary> dictionary = Arrays.asList( new Dictionary("7", "n1", "v1"), new Dictionary("8", "n2", "v2"), new Dictionary("9", "n3", "v3") ); for (Dictionary dictionaryRow : dictionary) { System.out.println("id: " + dictionaryRow.getValue_id()); System.out.println("name: " + dictionaryRow.getD_name()); System.out.println("value: " + dictionaryRow.getD_value()); } JavaRDD<Dictionary> rdd = sc.parallelize(dictionary); System.out.println("Total rdd rows: " + rdd.collect().size()); javaFunctions(rdd) .writerBuilder("chat", "dictionary", mapToRow(Dictionary.class)) .saveToCassandra(); }; }
The main problem here is an error:
java.lang.ClassCastException: com.datastax.driver.core.DefaultResultSetFuture cannot be cast to shade.com.datastax.spark.connector.google.common.util.concurrent.ListenableFuture at com.datastax.spark.connector.writer.AsyncExecutor.executeAsync(AsyncExecutor.scala:31) at com.datastax.spark.connector.writer.TableWriter$$anonfun$write$1$$anonfun$apply$2.apply(TableWriter.scala:159) at com.datastax.spark.connector.writer.TableWriter$$anonfun$write$1$$anonfun$apply$2.apply(TableWriter.scala:158) at scala.collection.Iterator$class.foreach(Iterator.scala:893)
….
So, to fix it – make sure that there is no cassandra-driver-core-3.1.0.jar and no
<dependency> <groupId>com.datastax.cassandra</groupId> <artifactId>cassandra-driver-core</artifactId> <version>3.1.0</version> </dependency>
at pom.xml
External Links
You could also read:
https://github.com/datastax/spark-cassandra-connector/blob/master/doc/7_java_api.md
Some DataSets theory:
http://spark.apache.org/docs/latest/sql-programming-guide.html#json-datasets
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
